Historical Search¶
StreamAlert historical search feature is backed by Amazon S3 and Athena services. By default, StreamAlert will send all alerts to S3 and those alerts will be searchable in Athena table. StreamAlert users have option to enable historical search feature for data as well.
As of StreamAlert v3.1.0, a new field, file_format, has been added to athena_partitioner_config
in conf/lamba.json, defaulting to null. This field allows users to configure how the data processed
by the Classifier is stored in S3 bucket, either in parquet or json.
Prior to v3.1.0, all data was stored in json. When using this format, Athena’s search performance
degrades greatly when partition sizes grow. To address this, we’ve introduce support for parquet
to provide better Athena search performance and cost saving.
Note
When upgrading to StreamAlert v3.1.0, you must set the
file_formatvalue to eitherparquetorjson, otherwise StreamAlert will raiseMisconfigurationErrorexception when runningpython manage.py build.For existing deployments, the
file_formatvalue can be set tojsonto retain current functionality. However, if thefile_formatis changed toparquet, new Athena tables will need to be recreated to load theparquetformat. The existing JSON data won’t be searchable anymore unless we build a separated tables to process data in JSON format. All of the underlying data remains stored in S3 bucket, there is no data loss.For new StreamAlert deployments, it is recommended to set
file_formattoparquetto take advantage of better Athena search performance and cost savings when scanning data.In an upcoming release, the value for
file_formatwill be set toparquetby default, so let’s change now!
Architecture¶
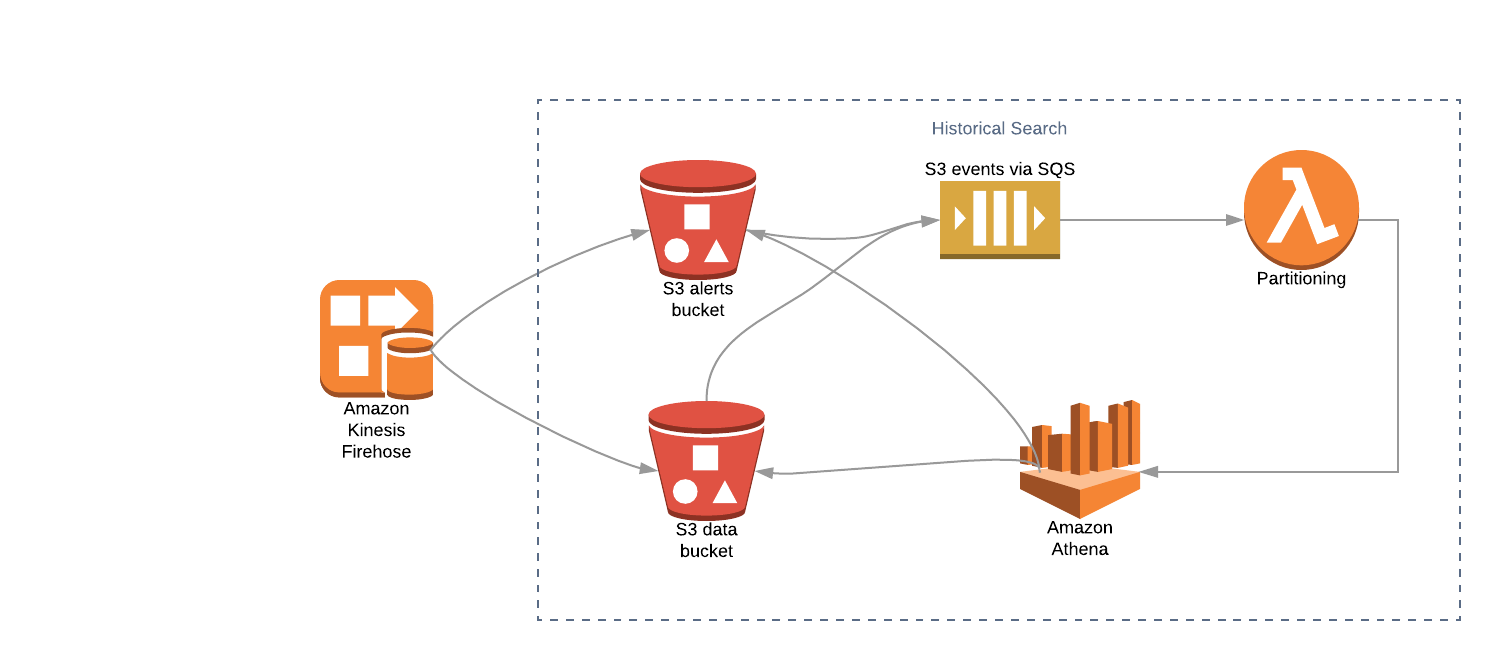
The pipeline is:
StreamAlert creates an Athena Database, alerts kinesis Firehose and
alertstable during initial deploymentOptionally create Firehose resources and Athena tables for historical data retention
S3 events will be sent to an SQS that is mapped to the Athena Partitioner Lambda function
The Lambda function adds new partitions when there are new alerts or data saved in S3 bucket via Firehose
Alerts, and optionally data, are available for searching via Athena console or the Athena API
Alerts Search¶
Review the settings for the Alerts Firehose Configuration and the Athena Partitioner function. Note that the Athena database and alerts table are created automatically when you first deploy StreamAlert.
If the
file_formatvalue within the Athena Partitioner function config is set toparquet, you can run theMSCK REPAIR TABLE alertscommand in Athena to load all available partitions and then alerts can be searchable. Note, however, that theMSCK REPAIRcommand cannot load new partitions automatically.StreamAlert includes a Lambda function to automatically add new partitions for Athena tables when the data arrives in S3. See Configure Lambda Settings
{ "athena_partitioner_config": { "concurrency_limit": 10, "file_format": "parquet", "log_level": "info" } }
Deploy the Athena Partitioner Lambda function
python manage.py deploy --functions athena
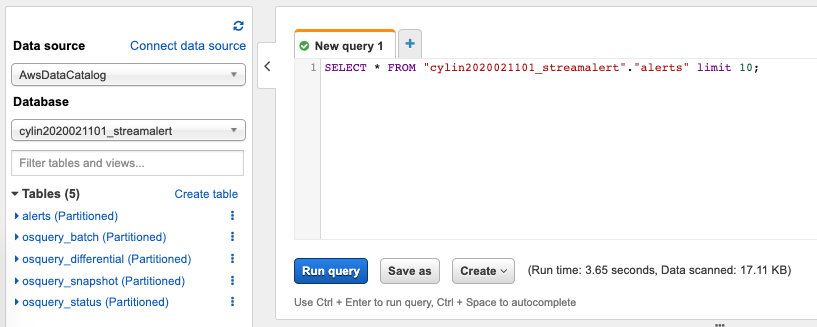
Search alerts in Athena Console
Choose your
Databasefrom the dropdown on the left. Database name is<prefix>_streamalertWrite SQL query statement in the
Query Editoron the right
Data Search¶
It is optional to store data in S3 bucket and available for search in Athena tables.
Enable Firehose in
conf/global.jsonsee Firehose (Historical Data Retention)Build the Firehose and Athena tables
python manage.py build
Deploy classifier so classifier will know to send data to S3 bucket via Firehose
python manage.py deploy --functions classifier
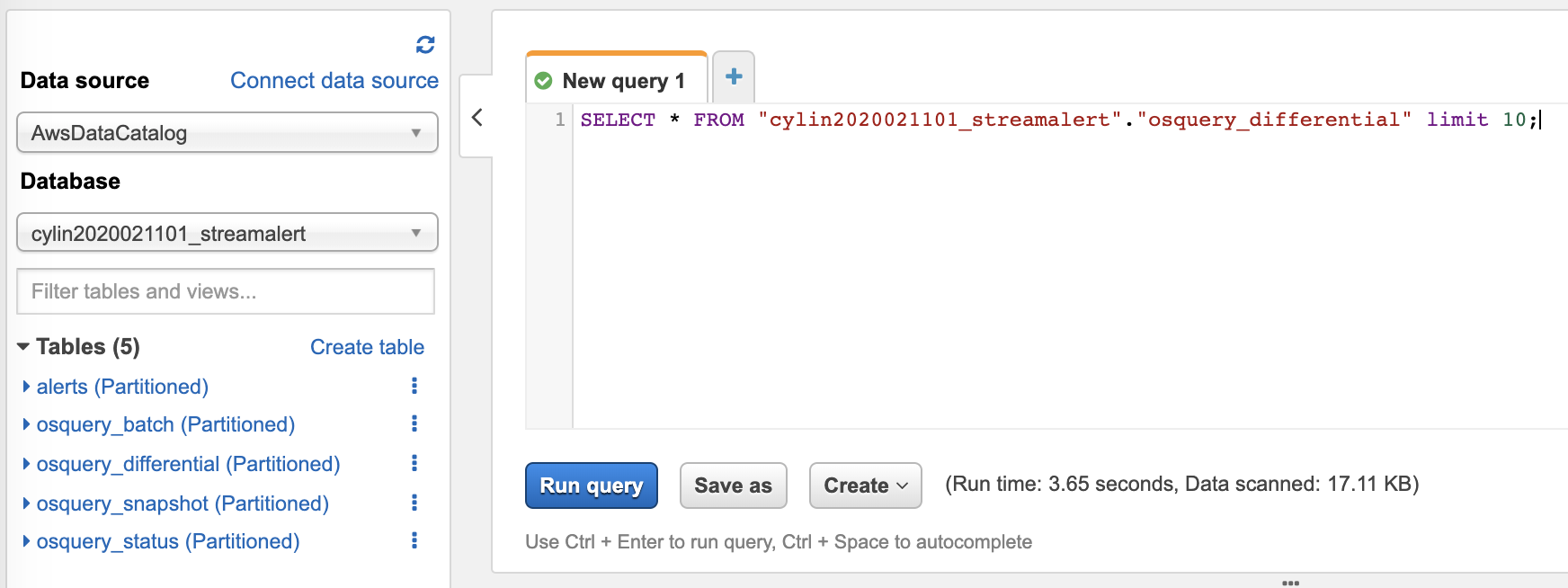
Search data Athena Console
Choose your
Databasefrom the dropdown on the left. Database name is<prefix>_streamalertWrite SQL query statement in the
Query Editoron the right
Configure Lambda Settings¶
Open conf/lambda.json, and fill in the following options:
Key |
Required |
Default |
Description |
|
Yes |
|
Enables/Disables the Athena Partitioner Lambda function |
|
No |
|
Enables/Disables logging of metrics for the Athena Partitioner Lambda function |
|
No |
|
The log level for the Lambda function, can be either |
|
No |
|
The amount of memory (in MB) allocated to the Lambda function |
|
No |
|
The maximum duration of the Lambda function (in seconds) |
|
Yes |
|
The alerts and data format stored in S3 bucket via Firehose, can be either |
|
No |
|
Key value pairs of S3 buckets and associated Athena table names. By default, the alerts bucket will exist in each deployment. |
Example:
{
"athena_partitioner_config": {
"log_level": "info",
"memory": 128,
"buckets": {
"alternative_bucket": "data"
},
"file_format": "parquet",
"timeout": 60
}
}
Athena References¶
Tip
Alerts and data are partitioned by
dtin the formatYYYY-MM-DD-hhTo improve query performance, filter data within a specific partition or range of partitions
SELECT * FROM "<prefix>_streamalert"."alerts" WHERE dt BETWEEN 2020-02-28-00 AND 2020-02-29-00